2023年1月22日追記:当初の表題は「NDLOCRのレイアウト判定処理に縦横双方向での行ボックス認識の追加を望みます #次々デジ備忘録」でしたが、現行NDL全文検索に用いられたのは令和3年度にLINE株式会社が受託したOCRテキスト化事業の成果であるとお教えいただいたので、表題と最初の1文を修正しました。図のキャプションは「NDLOCR」としていたものを「NDL全文検索」に改めましたが図中の注釈は「NDLOCR」となっております。「LINE版OCR」または「現行NDL全文検索」等と読み替えて下さい。
先日「東京築地活版製造所の「種字彫刻係取締」竹口庄太郎(正太郎)のこと」(https://uakira.hateblo.jp/entry/2023/01/06/012300)で取り上げた東京築地活版製造所の竹口庄太郎(正太郎)をNDL全文検索してみた際に気がついたことなのですが。
筆者は以前から、東京の活版印刷業組合が明治期に実施した組合員職工の表章について、印刷図書館で『印刷雑誌』を直接閲覧した際にメモを残しておりました。これを「個人送信」が始まる前、国会図書館デジタルコレクションの図書館間送信によって再確認し、次の記録があると認識していました。
- 1903明治36年、第1回表章(第1次『印刷雑誌』13巻4号〈https://dl.ndl.go.jp/pid/1499058/1/8〉)
- 1904明治37年、第2回表章(第1次『印刷雑誌』14巻4号〈https://dl.ndl.go.jp/pid/1499068/1/9〉)
- 1905明治38年、第3回表章(第1次『印刷雑誌』15巻4号〈https://dl.ndl.go.jp/pid/1499080/1/14〉)
- 1906明治39年、第4回表章(第1次『印刷雑誌』16巻4号〈https://dl.ndl.go.jp/pid/1499092/1/5〉)
また、この他に「築地活版製造所の勤続者表彰」というものが次の通り実施されています。
- 1916大正5年、築地活版勤続表彰(『日本印刷界』78号〈https://dl.ndl.go.jp/pid/1517497/1/60〉)
さて、築地活版の竹口ショウタロウは、当初「竹口正太郎」という漢字表記だったものが途中から「竹口庄太郎」に改名したものと思われます。
NDL全文検索で「竹口正太郎」と「竹口庄太郎」を各々チェックしてみたら、上記の表章履歴はどのような結果になるでしょうか(第3回表章と第4回表章では、竹口は受章者ではありません)。
- × 第1回表章を記録した第1次『印刷雑誌』13巻4号〈https://dl.ndl.go.jp/pid/1499058/1/8〉は「キーワードに該当するコマがありませんでした」になります。
- ○ 第2回表章を記録した第1次『印刷雑誌』14巻4号〈https://dl.ndl.go.jp/pid/1499068/1/9〉は目的のコマがヒットします。
- × 築地活版勤続表彰を記録した『日本印刷界』78号〈https://dl.ndl.go.jp/pid/1517497/1/60〉「キーワードに該当するコマがありませんでした」になります。
この違いは何に由来するのでしょうか。
明治大正期の複雑なレイアウトにも非常によく対応できているNDLOCRLINE版OCRが、現時点で苦手としている判断が、罫線のない縦組み「表」レイアウトだという具合に考えられます。「縦書き」と認識する範囲と「横書き」と認識してしまう範囲が混在しているようなのです。
第1次『印刷雑誌』13巻4号〈https://dl.ndl.go.jp/pid/1499058/1/8〉では「伊藤久次郎」「竹口正太郎」「八田秀治」の3名が縦書きで並んでいるのですが、「八竹伊」「田口藤」という横書きとして誤認されています。

第1次『印刷雑誌』14巻4号〈https://dl.ndl.go.jp/pid/1499068/1/9〉ではたまたま「竹口正太郎」が拾えるレイアウト認識になっていますが、一部に不自然なところが見受けられます。
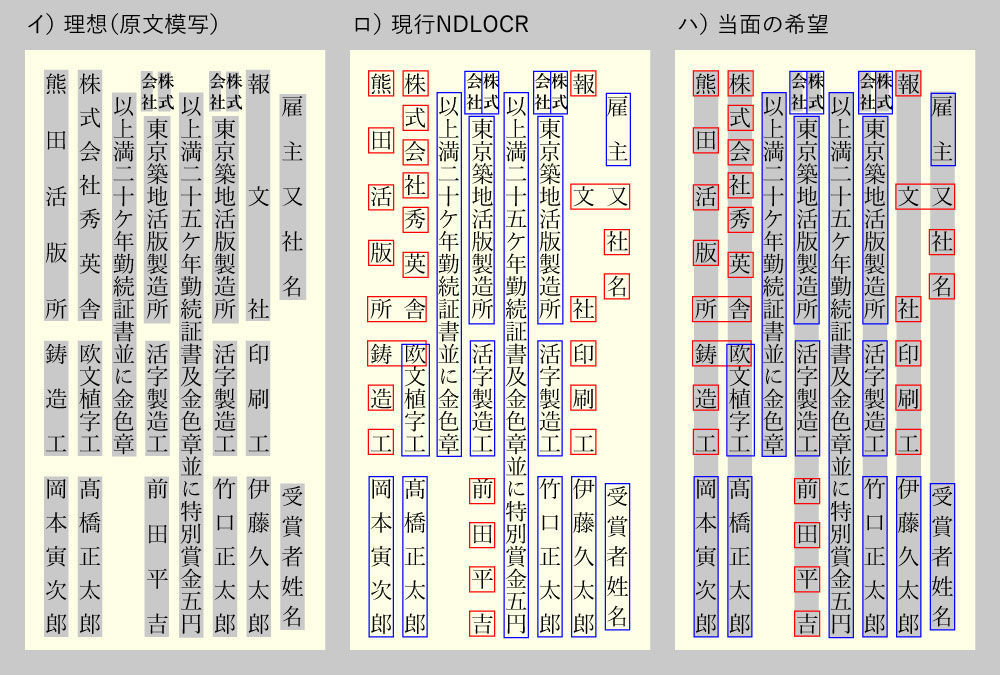
『日本印刷界』78号〈https://dl.ndl.go.jp/pid/1517497/1/60〉では「田村銀次郎」「岩田庄次郎」「竹口庄太郎」の3名が縦書きで並んでいるのですが、竹口の名が「竹口庄」までは縦書きとして認識され、そこから「太次次」という横書きになっていると誤認しているようです。

図表のキャプションなど、縦書きテキスト中の横書きテキストを認識できるように調教されたチューニングが、悪い方に作用してしまっている事例と思われます。
レイアウト検出のAIを適正に調教しなおすのが王道とは思いますが、「縦横が変な具合に混在している」という判断になる箇所については「全部縦組みとして読んだ場合」のOCR結果と、自動検出レイアウトでのOCR結果、これを両方記録できるようにしていただけないものかと、これまた切にお願い申し上げたき次第。